Использование компонентов Data Mining в продуктах Office 2007
Дополнительные компоненты MS Office 2007 для интеллектуального анализа данных на платформе SQL Server 2005 Analysis
Services предназначены для выявления скрытых шаблонов и взаимосвязей в данных для улучшения качества и глубины их анализа.
Для использования этих компонент вы должны иметь возможность подключаться к базе данных SQL Server 2005 Analysis Services.
Однако, опыт работы с компонентами SQL Server 2005 Analysis Services не обязателен.
Дополнительные компоненты MS Office 2007 для интеллектуального анализа данных доступны для бесплатной загрузки и состоят из следующих компонент:
- Средства анализа табличных данных для Excel – позволяет использовать Analysis Services для анализа и выявления закономерностей в данных из электронных таблиц Microsoft Excel.
- Клиентские компоненты Data Mining для Excel – Предоставляют возможность создания, настройки и сопровождения проекта Data Mining включая подготовку данных, построение, оценку и управление моделями Data Mining, получение результатов прогнозирования с использованием как табличных данных Excel в качестве источника, так и внешних источников, доступных базе данных Analysis Services.
- Шаблоны Data Mining для Visio – Предоставляют возможность графического представления, форматирования, описания и распространения результатов моделирования Data Mining в виде диаграмм.
Далее в этой статье мы предоставим обзорную информацию по системным требованиям, процессу установки и функциональности дополнительных компонент.
Подготовка к работе
Перед началом работы вы должны убедиться в установке следующих компонент:
- Microsoft .NET Framework 2.0 – Компоненты Data Mining для Office построены на платформе .NET Framework 2.0 и требуют поддержки программирования под Office 2007 для .NET.
- Microsoft Office 2007 – Необходимо установить Excel 2007 для работы со средствами анализа табличных данных и клиентских компонент для Data Mining. Следует установить Visio Professional 2007 для работы с шаблонами Data Mining для Visio. Установка должна включать опцию программирования под .NET (.NET Programmability Support).
- Дополнительные компоненты MS Office 2007 для интеллектуального анализа данных – Установка осуществляется загрузкой и запуском дистрибутива. На странице загрузки содержатся ссылки на страницы загрузки обязательных компонент, требуемых для работы системы.
- Средства соединения с SQL Server 2005 Analysis Services – Работа с моделями Data Mining посредством приложения MS Office требует связи с сервером SQL Server 2005 Analysis Services. Он может находиться как на локальной машине, так и на удаленном сервере, к которому у вас должен быть доступ. В любом случае, сервер Analysis Services должен быть правильно сконфигурирован для поддержки компонент Data Mining для Office. Установка компонент содержит мастер Getting Started, предназначенный для установки соединения и конфигурирования сервера Analysis Services.
После установки и конфигурирования всех необходимых приложений мы можем далее исследовать функциональность компонент Data Mining для Office.
Средства анализа табличных данных для Excel
Этот компонент предоставляет возможность проведения углубленного анализа табличных данных из MS Excel. Несмотря на тот факт, что для выполнения анализа используется вся мощь алгоритмов Data Mining, реализованных в Analysis Services 2005, конечному пользователю Excel не нужно знать всех тонкостей работы с Analysis Services и соответствующих алгоритмов.
Так как эта компонента является средством табличного анализа, вам необходимо знать, как создать или конвертировать существующую таблицу в таблицу Excel. Для получения более подробной информации загрузите видео-пример, освещающий работу со средствами анализа табличных данных.
Если после установки средства анализа табличных данных вы щелкните мышкой в любом месте внутри таблицы Excel, вы увидите следующую панель инструментов под пунктом меню «Табличные Данные» - Table Tools:

Рисунок 1 Средства анализа табличных данных для Excel 2007.
Каждый инструмент на этой панели вызывает простой интерфейс для выполнения одной из аналитических задач и формирования понятного отчета, позволяющего получить более глубокое понимание имеющихся данных:
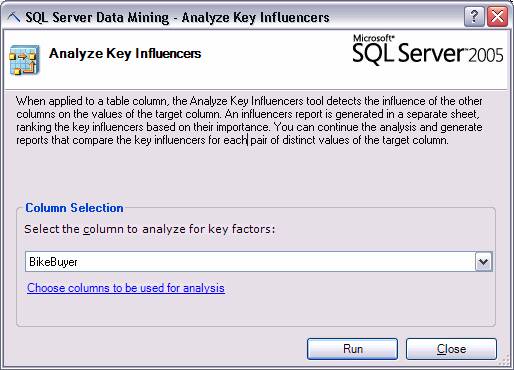
Рисунок 2 Пример интерфейса для выполнения одной из аналитических задач.
Давайте посмотрим на каждый инструмент на панели управления средствами для анализа табличных данных.
Анализ ключевых факторов
Этот инструмент производит анализ входных факторов в данных, которые имеют наибольшее влияние на определенный выходной атрибут. Например, если у вас есть список всех клиентов, анализ ключевых факторов может проанализировать факторы, являющиеся ключевыми для определения того какой из клиентов потратит наибольшую сумму денег на ваши товары или услуги.
Задача определения, какие поля в таблице являются решающими, не является очевидной. Например, поле, представляющее годовой доход клиента может быть не самым значимым фактором, выделяющим клиентов, заключающими с вами самые большие сделки. Важными могут быть совсем другие факторы, такие как число детей, географическое положение или комбинация этих факторов.
Ниже приведен пример результата анализа, выполненного этим инструментом:
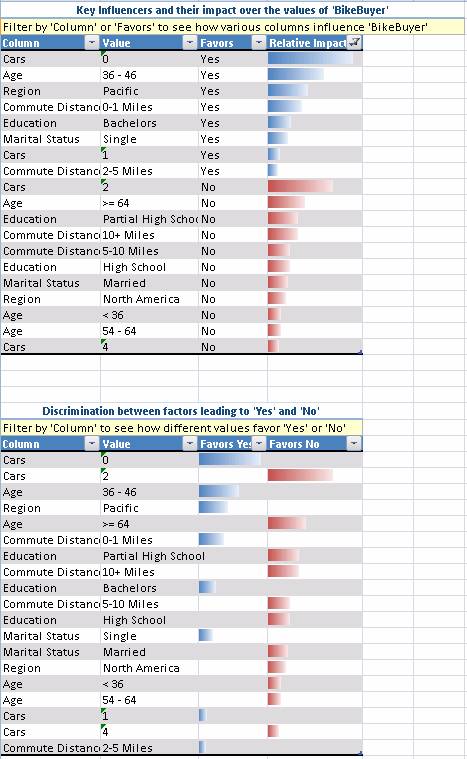
Рисунок 3 Пример результата анализа.
Выделение категорий
Инструмент Detect Categories (выделение категорий) определяет строки в табличных данных, имеющие похожие значения характеристик, и объединяет их в одинаковые категории.
Каждая выделенная категория описывается набором характеристик входящих в нее строк. Эти характеристики отличаются для различных категорий. Основываясь на этих характеристиках, вы можете дать категориям более понятное наименование. Например, категория, содержащая клиентов в возрасте 45-60 лет с доходам более 100000, может быть переименована в «успешных представителей послевоенного поколения». Разбиение данных в категории позволяет быстро идентифицировать естественные группировки в ваших данных, что может быть использовано, например, для формирования адресной маркетинговой кампании.
Этот инструмент также позволяет помечать каждую строку в исходной таблице названием содержащей ее категории.
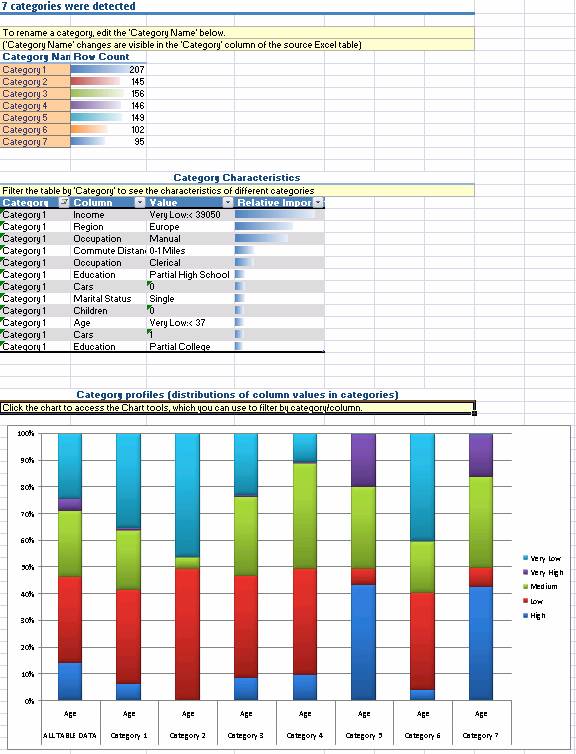
Рисунок 4 Инструмент Detect Categories (выделение категорий).
Автоматическое заполнение
Этот инструмент автоматически заполняет пропущенные в некоторых столбцах таблицы данные на основании типичных значений для строк со схожими значениями других столбцов.
Для реализации этой задачи используется алгоритм Data Mining, выявляющий шаблоны во всей совокупности заполненных данных и использующий эти шаблоны для заполнения пропущенных значений.
В дополнение к задаче заполнения пропущенных значений, инструмент автоматического заполнения также формирует отчет, в котором описываются найденные в данных шаблоны и используемые при заполнении пропущенных значений правила. Отчет отображается в форме, похожей на отчет об анализе ключевых факторов.
Прогнозирование
Инструмент прогнозирования позволяет осуществлять прогноз будущих значений временного ряда на основании его исторических данных с учетом обнаруженных моделью прогноза факторов и тенденций. Например, вы можете прогнозировать будущие значения продаж на следующие два месяца на основании продаж за прошлые два года. Инструмент добавляет значения прогноза в виде строк к вашим данным, а также формирует график, как показано ниже.
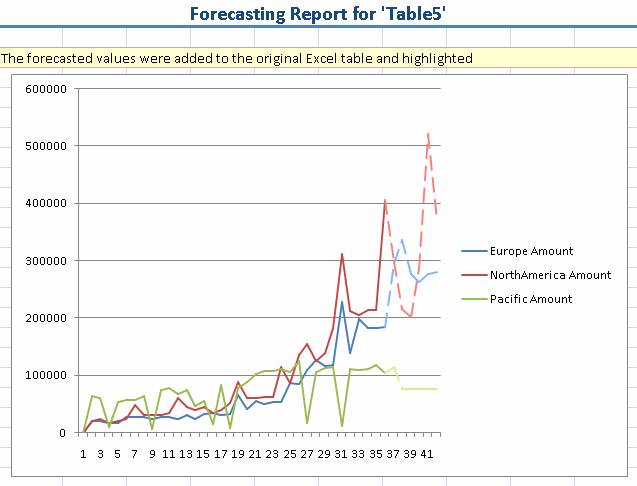
Рисунок 5 Прогнозирование временного ряда.
Выявление аномалий
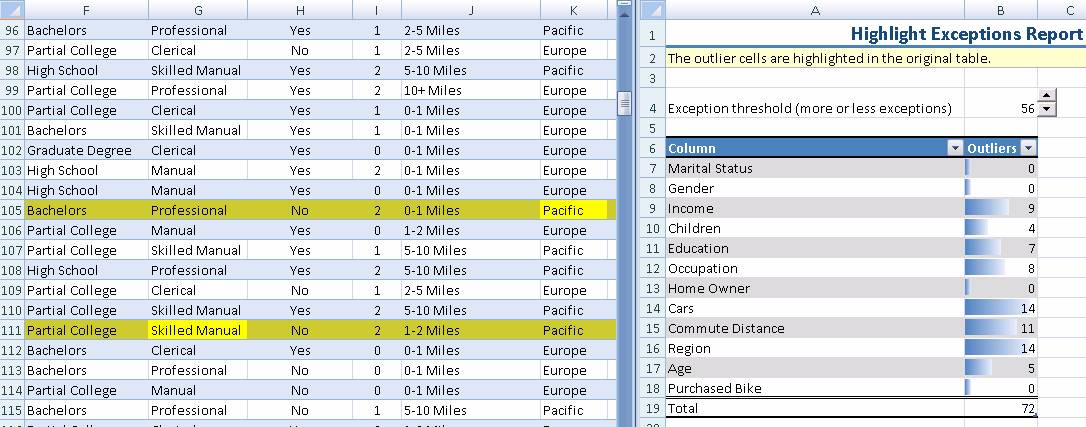
Этот инструмент анализирует и выявляет строки данных, не соответствующие стохастическим шаблонам, обнаруженным в остальных данных таблицы. Эти исключения могут быть вызваны ошибками при вводе данных или могут быть правильными необычными значениями, требующими дальнейшего анализа.
Выявление аномалий может быть очень полезно, так как они сильно искажают средние значения, тренды в данных и другие характеристики описательной статистики. Если аномалии вызваны ошибками при воде данных, вероятно, вы захотите исправить эти ошибки перед выполнением дальнейшего статистического анализа.
Инструмент выявления аномалий не только выделяет строки, не вписывающиеся в общие характеристики данных, но также выделяет значения в колонках, которые вероятно являются источником ошибки. Вы можете поменять значение в колонке, после чего вся строка подвергается повторной оценке для определения, является ли она все еще исключением.
Дополнительно, для управлением числом строк, помеченных как аномальные, отчет о найденных аномалиях можно настраивать. Настройка производится заданием граничного значения вероятности входных данных.
Ниже приведен пример отчета, формируемого инструментом выявления аномалий. Отчет комбинирует исходные данные и отчет об аномалиях:
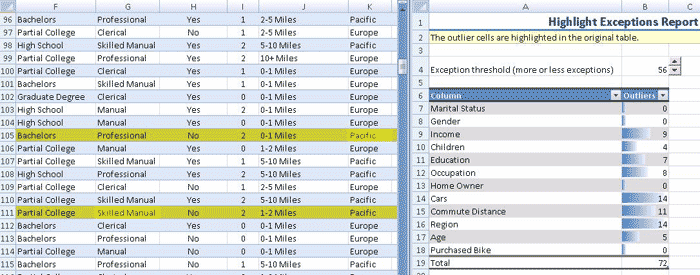
Рисунок 6 Выявление аномалий.
Анализ сценариев
Этот инструмент предназначен для моделирования двух типов сценариев и получать отчет о воздействии как на единственную строку, так и на всю таблицу исходных данных.
Подбор параметров
Подбор параметров – анализ и отчет о факторах, которые необходимо поменять для достижения указанного значения целевого параметра. Например, если компания хочет вырасти с десяти миллионов до пятидесяти миллионов долларов, этом инструмент сможет помочь определить как достигнуть этой цели, основываясь на факторах, присутствующих в анализируемых данных. Ниже приведен пример отчета для одной строки данных:
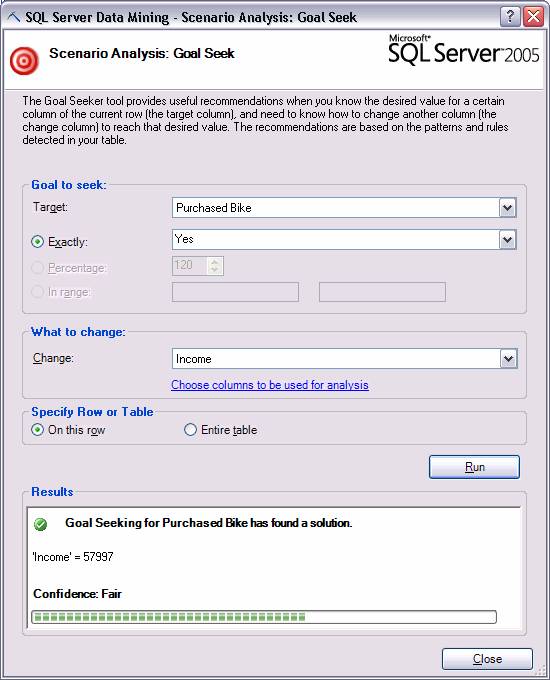
Рисунок 7 Подбор параметров.
Анализ «что-если»
Анализ «что-если» – анализ и формирование отчета о влиянии на выходной результат неких гипотетических изменений. Например, вы хотите увидеть эффект изменения в объемах продаж вашим клиентам если цена продукта будет увеличена. Анализ с использованием сценария «что-если» поможет вам определить, например, что увеличение цены не даст вам требуемый результат, но увеличение гарантийного срока вполне способно этот результат обеспечить. Ниже приведен пример отчета для одной строки данных:
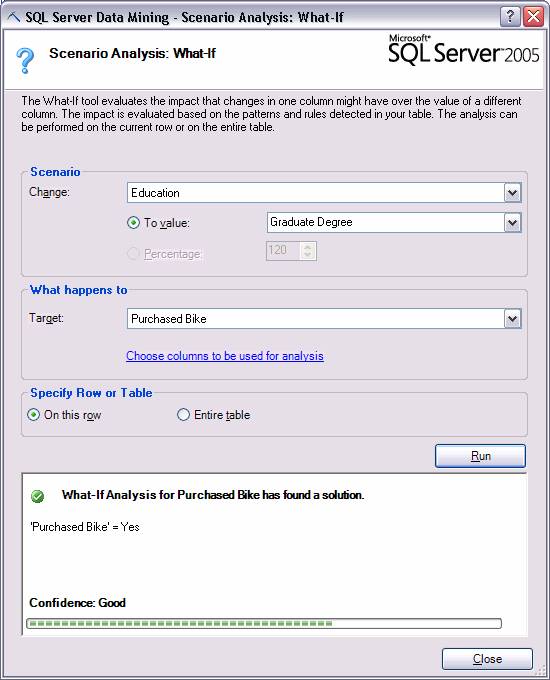
Рисунок 8 Анализ «что-если».
Соединение
Кнопка «соединение» предназначена для создания и настройки соединения с базами данных Analysis Services.
Справка
Кнопка «Справка» предоставляет доступ к документации, а также к мастеру Getting Started, а также к сопутствующим интернет-ресурсам.
Клиент Data Mining для Excel
Клиент Data Mining для Excel позволит вам провести полный цикл интеллектуального анализа данных посредством клиента Excel с использованием данных электронных таблиц или внешнего источника, доступного базе данных Analysis Services.
Если вы установили клиент для Data Mining, вы увидите панель инструментов Data Mining:

Рисунок 9 Панель инструментов клиента Data Mining для Excel 2007.
Организация слева направо и группировка кнопок на панели инструментов отражает типичный порядок выполнения задач в проекте анализа данных. Каждая секция подробно описана ниже.
Подготовка данных
Задача выбора правильных атрибутов из источника данных и представление их в правильном формате занимает высокий процент времени в процессе построения аналитических моделей. Эта секция предоставляет инструменты для основных задач подготовки данных до начала их углубленного анализа.
- Исследование данных – служит для построения графика распределения дискретных и непрерывных переменных, а также для добавления группировок в исходные данные.
- Очистка данных – служит для удаления выбросов и для изменения значений меток дискретных данных (например, если исходные данные содержат значения «M» и «F» в колонке пола, а вы предпочитаете видеть эти значения как «мужской» и «женский» для ясности презентации результатов).
- Секционирование данных – служит для разбиения исходных данных на обучающее и тестовое множество посредством случайных выборок исходных данных.
Ниже приведен снимок экрана, изображающий как вы можете удалить значения ниже заданного значения:
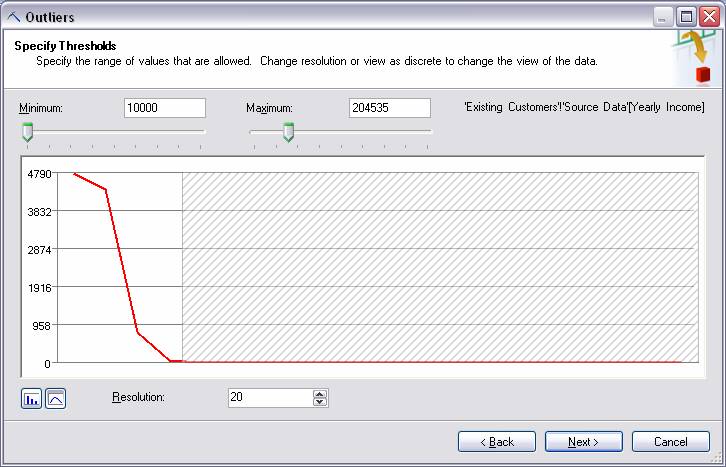
Рисунок 10 Очистка данных.
Построение моделей
Эта секция предназначена для создания и обработки моделей анализа данных. Она предоставляет мастера, которые помогают вам построить распространенные типы моделей Data Mining без необходимости разбираться в соответствующих алгоритмах и связанных с ними параметров, которые выполняются на сервере. Также, в этой секции есть возможности, позволяющие пользователю выбрать конкретный алгоритм и настроить дополнительные параметры.
Ниже приведена страница из мастера ассоциативных правил, служащая для нахождения ассоциаций в транзакционных данных:
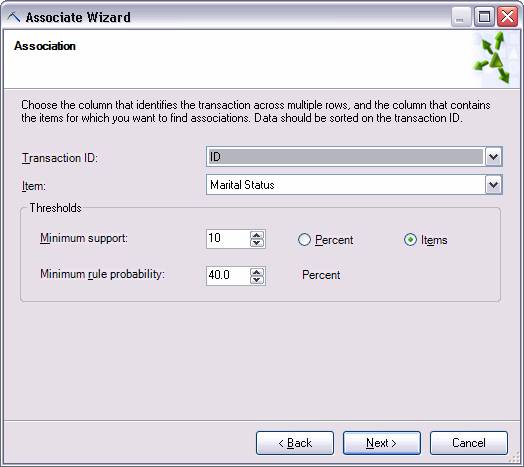
Рисунок 11 Мастер ассоциативных правил.
Точность и проверки
Эта секция содержит вызов графиков для валидации и тестирования точности моделей анализа данных.
- График точности – график точности результатов модели по сравнению с тестовыми данными, представляется в виде диаграмм роста (lift chart) для моделей классификации или в виде диаграмм рассеяния (scatter plot) для регрессионных моделей.
- Классификационная матрица – таблица правильных и неправильных результатов классификации на основании известных результатов тестовых данных.
- Диаграмма прибыли – графическое моделирование прибыли для запланированных кампаний на основе заданных пользователем параметров издержек.
Ниже приведен график точности, сформированный клиентом анализа данных в Excel, изображающий типичную модель, точность прогноза которой находится между случайным выбором и идеальной моделью:
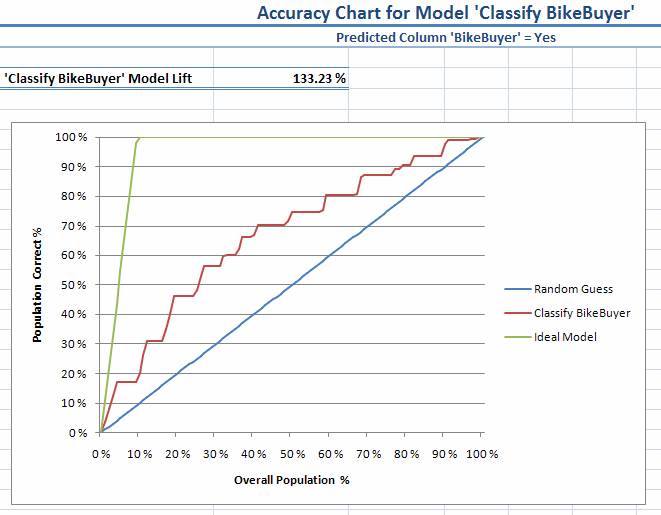
Рисунок 12 график точности, сформированный клиентом анализа данных в Excel 2007.
Использование модели
Эта секция покрывает две стандартные задачи, обычно выполняемые с обученными моделями:
Управление
Предоставляет возможность управления существующими моделями в базе данных Analysis Services, к которой вы подсоединены. Вы можете переименовать, удалить, очистить, перестроить, экспортировать, импортировать структуры анализа данных и модели, как показано на рисунке:
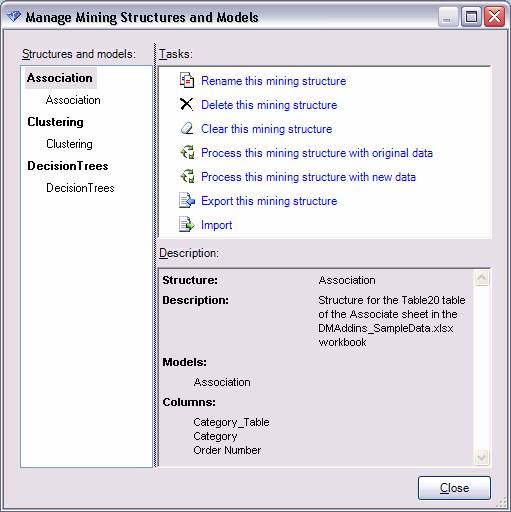
Рисунок 14 Управление существующими моделями в базе данных Analysis Services.
Кнопки Соединение и Справка идентичны уже описанным кнопкам на панели инструментов анализа табличных данных. Дополнительная кнопка Запись позволяет проследить команды, посылаемые к базе данных Analysis Services клиентским приложением.
Шаблоны Data Mining для Visio
После установки дополнительных шаблонов анализа данных вы получаете возможность распространять содержание и результаты моделей анализа данных в качестве комментируемых диаграмм Visio. Вы также можете опубликовать эти диаграммы в качестве интерактивных веб-страниц.
Запустив Visio 2007 после установки шаблонов анализа данных, вы увидите шаблон Microsoft Data Mining в списке шаблонов, как показано ниже:

Рисунок 15 Шаблон Microsoft Data Mining в Visio 2007.
После открытия шаблона вы можете перетащить один из следующих объектов Visio на рабочий лист, при этом появится диалоговая форма, которая позволит соединиться с существующей моделью в базе данных Analysis Services, после чего вы сможете отредактировать диаграмму.
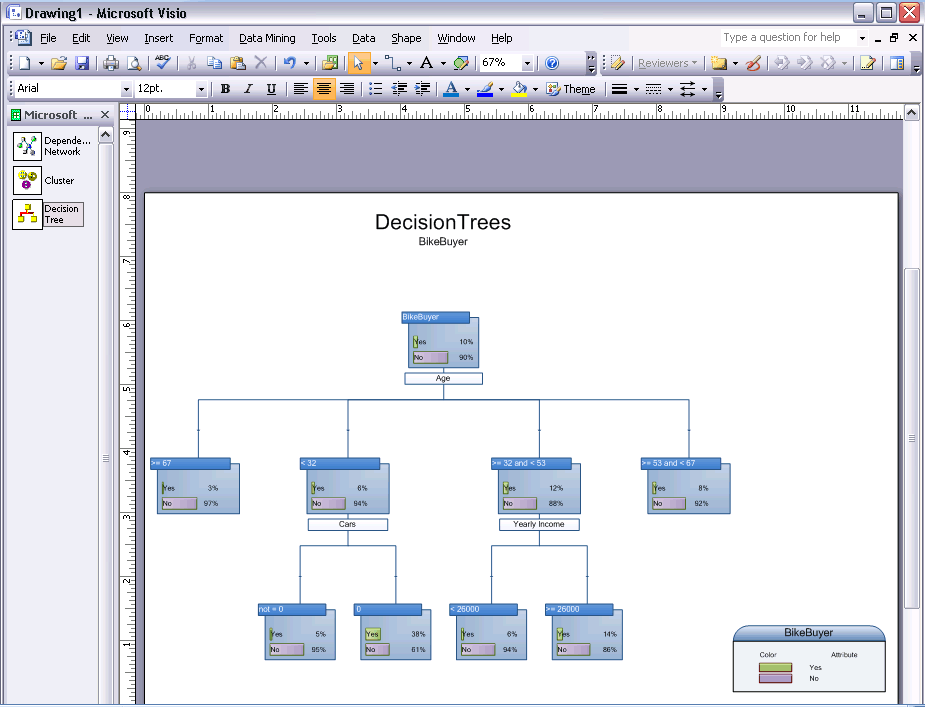
- Дерево решений – создает диаграммы для моделей, созданных с помощью алгоритмов дерева решений (Microsoft Decision Trees), линейной регрессии (Microsoft Linear Regression) и логистической регрессии (Microsoft Logistical Regression). Диаграмма поддерживает различные схемы отображения узлов для классификационных и регрессионных деревьев.
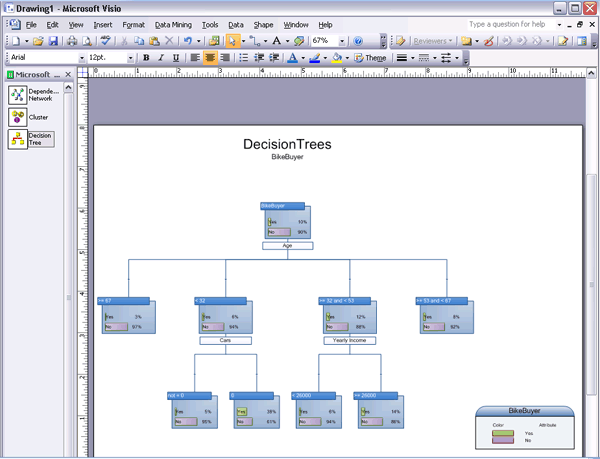
Рисунок 16 Дерево решений в Visio 2007.
Для регрессионных деревьев узлы показывают математическое ожидание и среднеквадратическое отклонение с графиком распределения вместо гистограммы состояний.
-
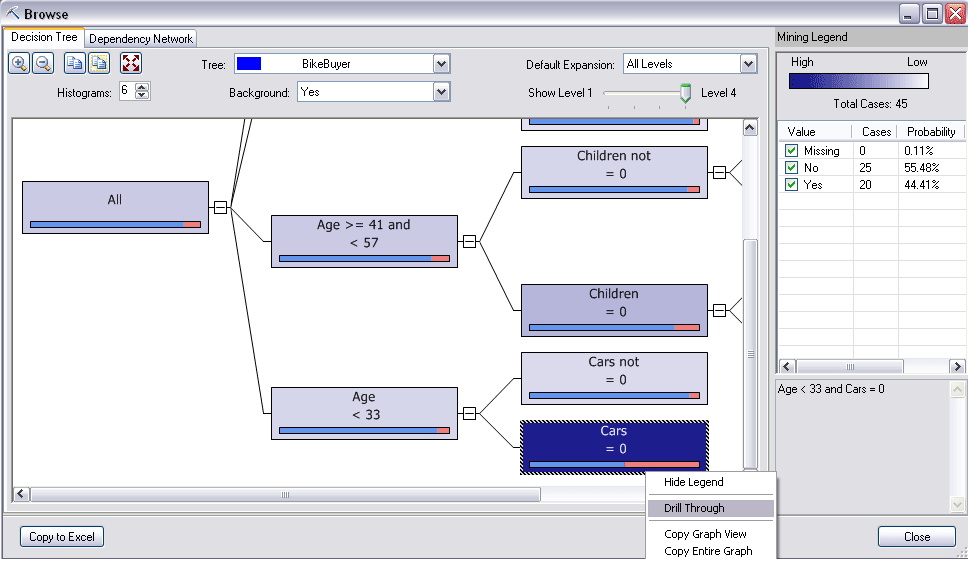
Сеть зависимостей – создает диаграмму на основании результатов моделей анализа данных, созданных с помощью алгоритмов дерева решений (Microsoft Decision Trees), упрощенного алгоритма Байеса (Microsoft Naive Bayes), ассоциативных правил (Microsoft Association Rules).
Пользовательский интерфейс позволяет выбрать набор узлов, отвечающих условиям запроса, а затем получить подмножество исходных данных, входящих в выбранные узлы. Это полезно для интерактивного «проваливания» в исходные данные при просмотре и анализе наиболее интересных сегментов.
-
Кластеры – создает диаграмму на основании модели, созданной с помощью алгоритма кластеризации (Microsoft Clustering). Вы можете представить результаты с помощью только визуальных объектов или также с указанием характеристик кластеров, или с графиками различий. Ниже представлен пример с представлением кластеров вместе с характеристиками:
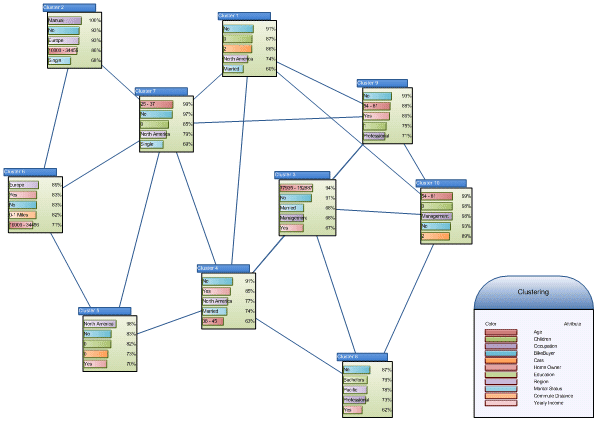
Рисунок 17 Кластерная диаграмма в Visio 2007.
В дополнение к возможности поддержки стандартных и настраиваемых схем, а также возможности комментирования и вставки дополнительных текстовых и графических элементов, объекты шаблонов анализа данных позволяют:
- раскрывать и скрывать под-деревья
- копировать и перемещать под-деревья на новую страницу
- менять цветовые схемы
- заменять стандартные графические объекты другими
- управлять тенями
Заключение
Независимо от степени вашего знакомства с концепциями и практикой Data Mining, вы можете успешно использовать дополнительные компоненты анализа данных SQL Server 2005 для Office 2007 с целью осуществлении углубленного анализа данных.
|